壹 前言
隨著 AI 多模態能力的快速發展,影像問答(VQA, Visual Question Answering)、視覺對話(Visual Dialog)[1]等應用已經成為主流。然而,建立在聲音理解基礎上的音訊問答(Audio Question Answering, AQA) 是更具挑戰卻也更具潛力的新興方向:它從傳統的聲音辨識(例如聲音分類或字幕生成[2])進階到理解事件背景、聲音順序與情境推理[3],真正做到讓機器「聽懂場景,並思考回答」。
同時,在大型語言模型(LLM)取得突破後,專為音訊設計的 Audio LLM 開始成為語音與環境聲識別的下一代語言理解方案:它們直接從聲音訊號中理解語境、回答自然語言問題,打破以往需要先轉錄再處理的傳統流程,提升問答互動效率與應用靈活性。
接下來的文章中將更深入介紹技術特點,並探索這類技術的應用潛力。
貳 科技發展現況
一、 何謂音訊問答
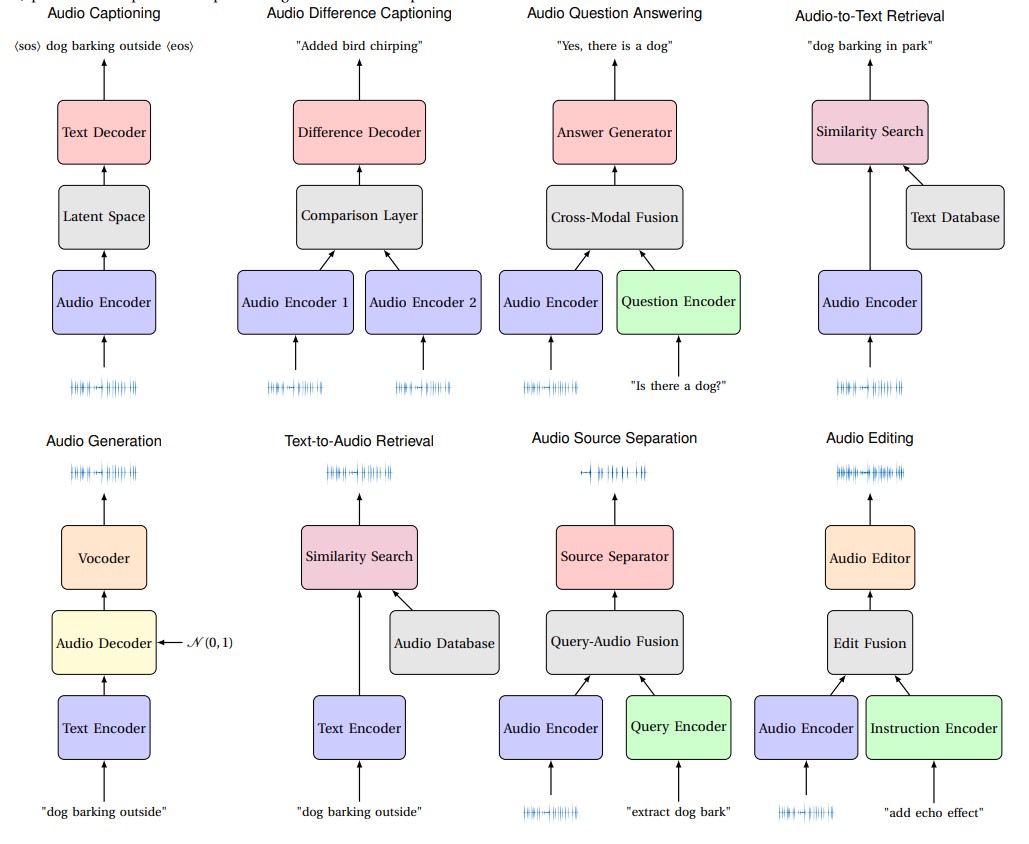
音訊問答(Audio Question Answering, AQA)是「音訊-語言」任務中的一項具體應用。圖 1 展示了「音訊-語言」資料集中常見的八大應用類型[4],而其中之一即為 AQA 任務,專注於「音訊 + 問句 → 自然語言回答」的互動形式,透過「針對某段音訊回答一個問題」的操作方式包裝模型。 問答範例如下:
- 聲音事件分類:「請基於聲學特徵,分類此語音片段之聲音事件。」→「高頻且頻率快速變化 → 警報聲」- 音訊字幕生成:「請用一句話描述此音訊。」→「救護車警報聲迴盪,交通噪音逐漸消退,伴隨引擎轟鳴聲。」
- 時序分析:「對音訊片段中的聲音事件進行分類,並輸出每個音訊事件的時間戳。」→「車輛加速聲:[2.0s-10.0s];一般撞擊聲:[6.7s-6.8s]」
二、 Audio LLM概念與框架
音訊問答(AQA)是一種應用任務,而要達成這項任務,必須依賴Audio LLM這類多模態模型,透過它實現整合音訊與語言理解並生成答案,簡言之,Audio LLM是支撐AQA任務的核心技術。Audio LLM技術的動機源自於將聲音分類模型與大型語言模型(LLM)的優勢結合在一起。聲音分類模型在處理音頻數據方面具有卓越的能力,能夠有效地識別和分類不同的聲音類型,如車聲、雨聲、人聲等,具備「聆聽」的能力。而大型語言模型則在自然語言處理上展現出強大的「思考」和「理解」的能力,例如可說明不同犬種吠聲的辨識方法,從聲學特徵之頻率及持續時間等差異區分。若能將這兩者結合在一起,則能補足彼此缺乏的能力,不但擁有聲音感知能力(聆聽),還能夠進一步理解這些聲音在場景中的意義(思考和理解),並生成相應的文本描述。
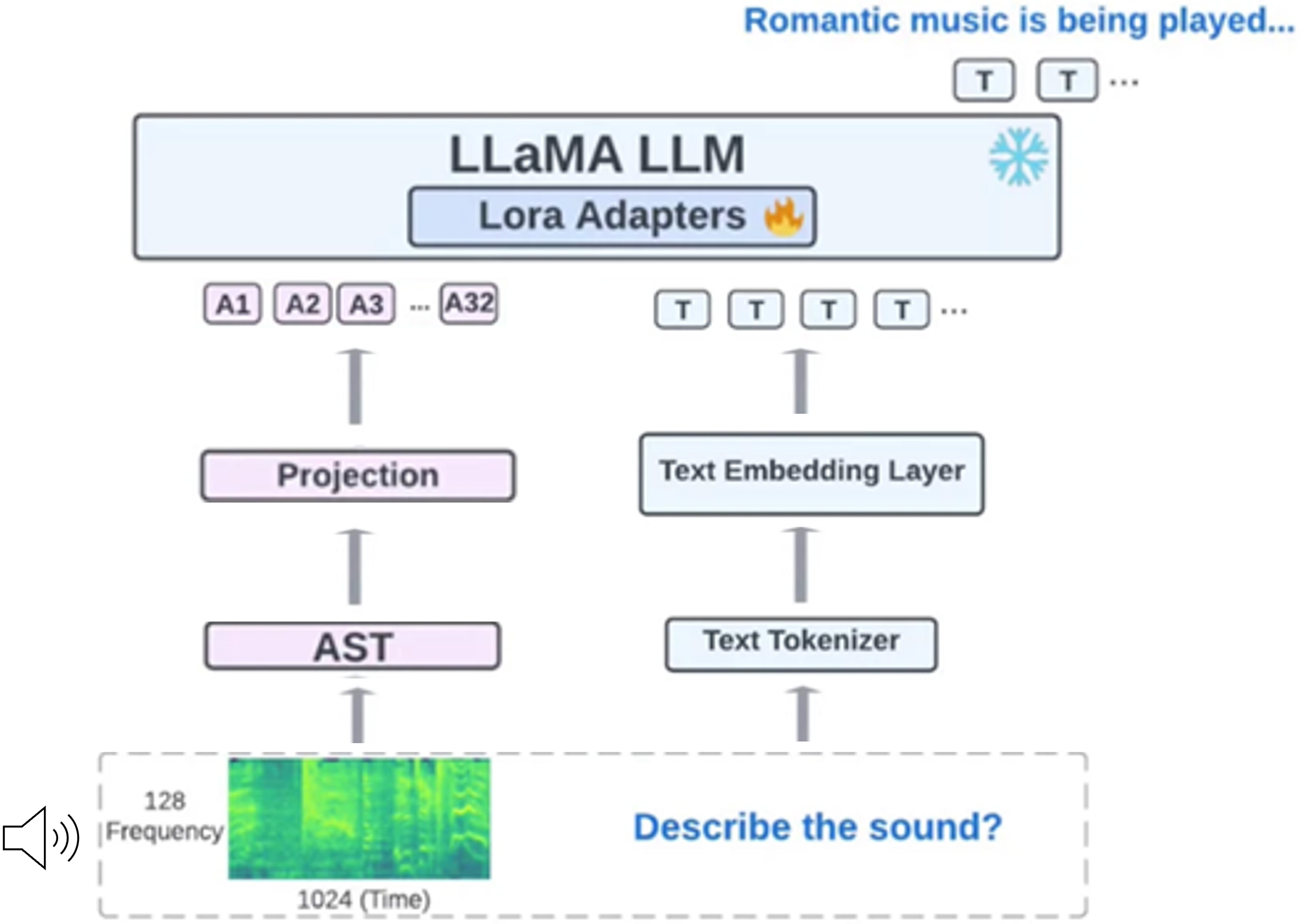
以MIT-IBM Watson AI Lab所提出的LTU模型框架[5]為例,詳見圖2。整個流程從輸入原始音訊開始。系統會先把聲音轉換成像「聲音照片」一樣的圖像格式(稱為時間-頻率圖),每張圖都有 128 個頻率區段與 1024 個時間切片,這些聲音圖像會進入名為 AST(Audio Spectrogram Transformer)的模組,把每塊聲音訊號變成數字向量,再由投影模組(Projection)將這些「音訊向量」轉換成符合語言模型輸入維度的嵌入表示。這些表示方式比傳統的語音轉文字(如字幕)來得更精細,因為它保留了聲音中更細膩的資訊與時間變化,對 AI 而言更容易理解聲音的內容與語氣變化。另一方面,系統也會同時把輸入的文字送進文字斷詞器(Text Tokenizer)進行字詞單位切割,再透過文字嵌入層(Text Embedding Layer)轉成數值向量的嵌入表示,這樣一來,電腦就能同時理解聲音與文字。最後,這些音訊與文字的資訊會一同送入LLaMA[6]語言模型中,進行推理與理解。
模型問答實際範例如下:
(輸入音訊為一槍聲片段)
- 聆聽:「用一句話描述這段音訊」→「聽到槍聲和腳步聲,隨後是一名男子說話聲」
- 思考:「這段聲音可能的場景是什麼? 」→「可能這名男子正在穿越戰區或危險區域」
- 理解:「如果我聽到這個聲音,我應該怎麼做? 」→「你應該立即尋找掩護並呼叫求助,因為這可能是危險或緊急情況的跡象」
三、 潛在應用
音訊問答與 Audio LLM 技術的發展,展現出處理複雜聲音情境的潛力,特別是在需要即時反應或理解多樣聲景的情境中,這類技術未來有機會與 IoT 裝置、智慧感測系統等結合,以下列出幾項潛在的應用方向:
• 無障礙輔助: 為聽障者即時轉換環境音為情境描述文字,如「後方有腳步聲」、「左側有車輛靠近」、「有人在說話」,提供環境提醒與安全提示。
• 居家安防監控: 與IoT結合之監控系統可實時辨識門鈴聲、破窗聲、孩童哭泣、水流聲等音訊事件,並自動通報住戶,提高居家安全與應變速度。
• 交通安全輔助: 實時分析車流噪音、救護/消防警報聲、行人聲音與背景聲響,預測視線盲區與環境遮蔽風險以預防事故,提升自駕車及智慧城市的安全與環境感知能力。
• 工廠設備監測: 檢測機械摩擦聲、敲擊聲、爆裂聲等異常聲音,能及早預警設備故障,減少突發停機,提升維修效率與生產安全。
• 生態環境監控: 自動辨識蟲鳴鳥叫、稀有物種、水流與風聲等生態聲景,快速評估物種多樣性與生態狀態,提升環境保育效率。
四、 現實挑戰
儘管Audio LLM展現強大的音訊理解能力,近期研究指出這類模型在實務應用中仍面臨顯著挑戰[7][8]:模型可能出現聲音幻覺(聽見不存在的事件)、時間順序錯誤(聽不出先後邏輯)、誤認聲音來源(誤將警報當音樂)、傳統評估不全面(沒抓出以上弱點)等問題,這些問題若發生在真實場景中,可能造成決策錯誤與安全風險。
此外,在資料方面,Audio LLM在模型訓練時仰賴大量audio-text對應資料,然而此類標註資料較稀少,且聲音類別分布不均,導致模型容易偏向常見音源(如人/車聲),而對少數類型的泛化能力不足。在處理罕見或高風險聲音時,必須透過專門的模型調整策略,以避免漏判或誤判之情形。
參 結論
Audio LLM透過音訊問答包裝成類似自然對話的互動方式,提升了多模態理解與人機互動的流暢性,這股技術趨勢不只是「能聽懂聲音是什麼」,更深入「理解聲音發生的語境與邏輯」。當然,要將此技術真正推向高安全標準的應用,如智慧交通/居家安防,還需要持續強化模型的泛化能力與判斷可靠性。
未來研究應聚焦於強化辨識穩定性、資料多樣性擴增等方向,才能真正落地支援音訊問答應用於高安全需求場域,並在人機音訊交互中展現高度的理解力、安全性與信任度。
肆 參考文獻
[1] Gi‑Cheon Kang, et al. "The Dialog Must Go On: Improving Visual Dialog via Generative Self‑Training." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023.
[2] Anirudh S. Sundar, et al. "Multimodal Attention Merging for Improved Speech Recognition and Audio Event Classification." ICASSP 2024 Workshop on Self‑Supervision in Audio, Speech and Beyond (workshop paper), arXiv:2312.14378, 2024.
[3] Chao‑Han Huck Yang, Sreyan Ghosh, et al. "Multi‑Domain Audio Question Answering Toward Acoustic Content Reasoning in The DCASE 2025 Challenge." arXiv:2505.07365, 2025.
[4] Wijngaard, Gijs, et al. "Audio-Language Datasets of Scenes and Events: A Survey." arXiv:2407.06947, 2025.
[5] Yuan Gong, et al. "Listen, Think, and Understand." Proceedings of the 12th International Conference on Learning Representations (ICLR), 2024.
[6] Hugo Touvron, et al. "Llama: Open and efficient foundation language models." arXiv:2302.13971, 2023.
[7] Chun Yi Kuan, et al. "Understanding Sounds, Missing the Questions: The Challenge of Object Hallucination in
Large Audio Language Models. " Interspeech 2024 , arXiv:2406.08402, 2024.
[8] Chun‑Yi Kuan and Hung‑yi Lee. "Can Large Audio‑Language Models Truly Hear? Tackling Hallucinations with Multi‑Task Assessment and Stepwise Audio Reasoning. " arXiv:2410.16130, 2024.