壹 前言
2022年11月,由OpenAI開發的大語言模型應用ChatGPT的出現,掀起了一股AIGC(AI Generated Content, 人工智慧生成內容)風潮。ChatGPT在創意寫作、翻譯、客服等領域表現出色,在短時間內就吸引了眾多開發者和企業的關注,當時更成為用戶數成長最快的服務[1](於2023年七月被Threads超越)。
ChatGPT使用的核心技術其實並非全新技術,在自然語言處理(Natural Language Processing)領域中早就已經發展了許多基於transformer演算法的預訓練模型如圖1。OpenAI以其發展的GPT(Generative Pre-trained Transformer)相關模型來發展對話機器人,也就是ChatGPT。它不僅可以生成更流暢、更有創意的文字,還可以如同人類般的理解複雜語法和邏輯。這為AIGC的發展提供了新的可能,也為許多領域的應用帶來了新的機會。
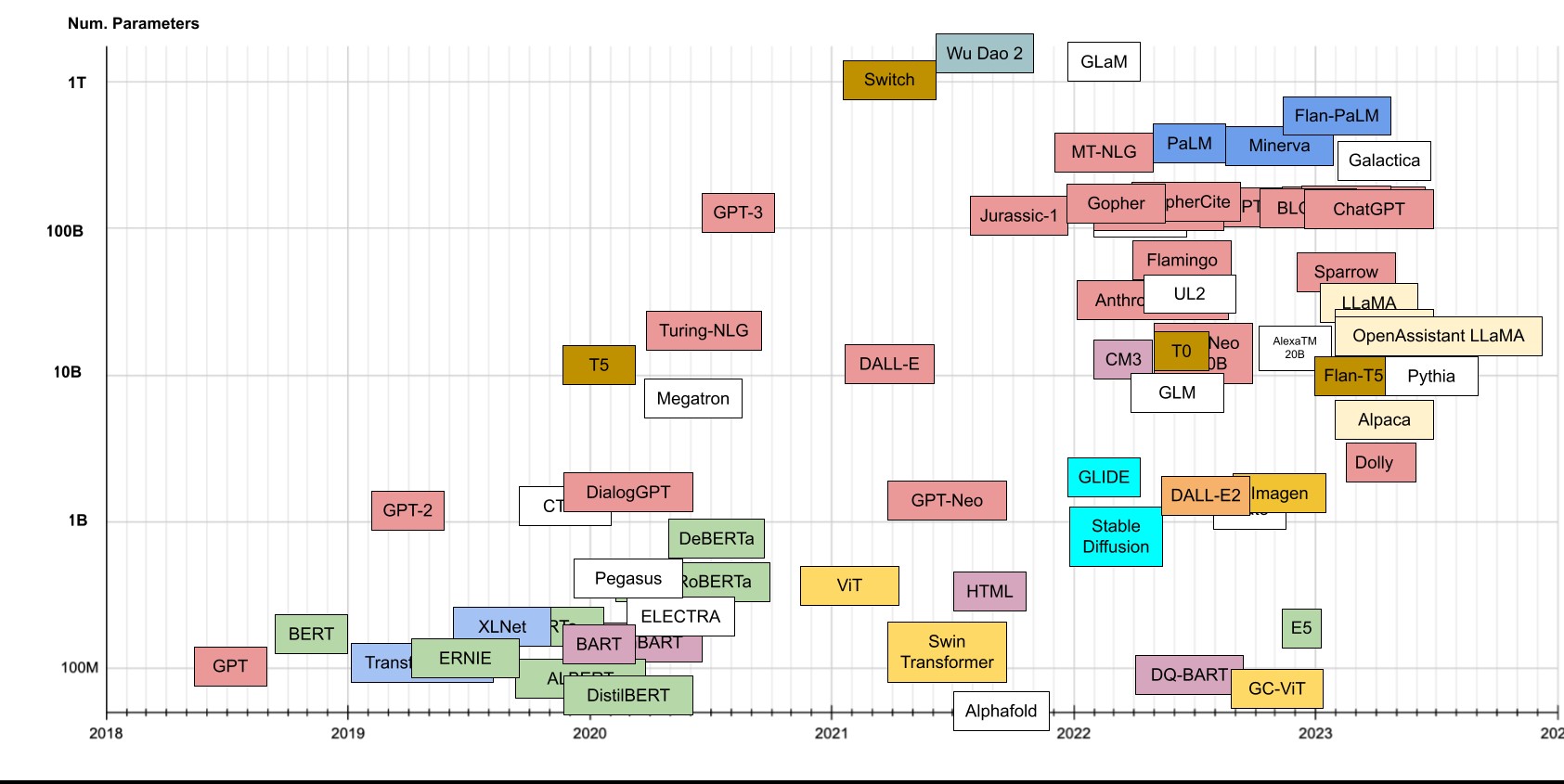
坊間已有許多介紹讓ChatGPT更聰明的應用方式如Prompt Engineering(提問工程)、CoT(Chain-of-Thought,思維鍊)。本文主要由軟體開發角度探討AIGC技術如何應用在網路維運管理領域,並介紹如何建置與應用大語言模型,包含外部API方案與本地端建置私有大語言模型。
貳 科技發展現況
一、 AIGC(AI Generated Content, 人工智慧生成內容)
AIGC是指由人工智慧(AI)系統生成的各種數位內容,包括但不限於文字、圖像、語音和影像。透過深度學習、生成對抗網路(Generative adversarial networks,GAN)、transformer、擴散模型(Diffusion model)等技術的應用,AIGC能夠模擬、生成高品質的內容,使得這些生成的內容在視覺、聽覺和語言方面變得更加真實和可信。以下為各領域的一些應用與介紹:
文本生成:文本生成領域中的AIGC通常稱為大語言模型(large language model,LLM),這些模型可以生成自然、連貫的文章,甚至能夠模擬不同風格和作者的文字風格或是理解邏輯。此領域大部分以對話機器人的方式提供互動介面,知名應用如ChatGPT[3]、Claude[4]、Bard[5]、Perplexity[6]。
程式碼生成:程式碼生成是文本生成領域的一個子集,所以上述之應用都可以直接產生可用的程式碼內容。但真正要能輔助程式設計師還需要針對程式碼知識做更多的微調,甚至是考量到如何自動驗證所產生的程式碼。知名應用如GitHub Copilot[7]、SQL Chat[8]。
圖像生成: AIGC能夠創建逼真的圖像,甚至包括人臉、風景、動物等多種場景,甚至使用不同繪畫風格。這為藝術創作、設計等領域提供了嶄新的可能性。如果需要產生影片,只要產生足夠多的連續圖像即可組成一段影片。常用的技術有GAN(Generative adversarial networks,對抗生成網路)與Diffusion Model,知名應用如Midjourney[9]、ChatGPT Vison[10]、Bing Image Creator[11]、Leonardo.Ai[12]。
語音生成: AIGC能夠合成自然流暢的語音,這在虛擬助手、語音劇本方面可以發揮很大功用。在這領域中ElevenLabs提供許多不同應用如Speech Synthesis (語音合成) [13]、Dubs (配音) [14]、VoiceLab (聲音實驗室) [15]、Voice Library (聲音函式庫) [16]。
AIGC的發展帶來了許多機會,同時也引起了一些關於內容真實性、版權問題、道德擔憂以及技術濫用的問題。隨著AIGC的不斷發展,產業界和學術界都在積極探討相應的法律、道德和技術規範,以確保這一領域的發展能夠取得正面效果並促進創新。
二、 網路維運管理領域
電信公司在網路維運管理領域的最終目的是維持網路的穩定,而維運人員面臨到的最大痛點是複雜的網路與維運支持系統 (Operations support system,OSS)。這領域會產生極其龐大的文本數據,包括日誌記錄、設備數據、申告、報表等資訊。這些數據源泉龐雜,如果使用傳統的方法要從中提取價值和洞察資訊,可能會過於繁瑣且效率低下,甚至極度依賴個人的領域知識與專業素養。因此以數據驅動的大語言模型成為在這一領域中實踐的最佳方向。
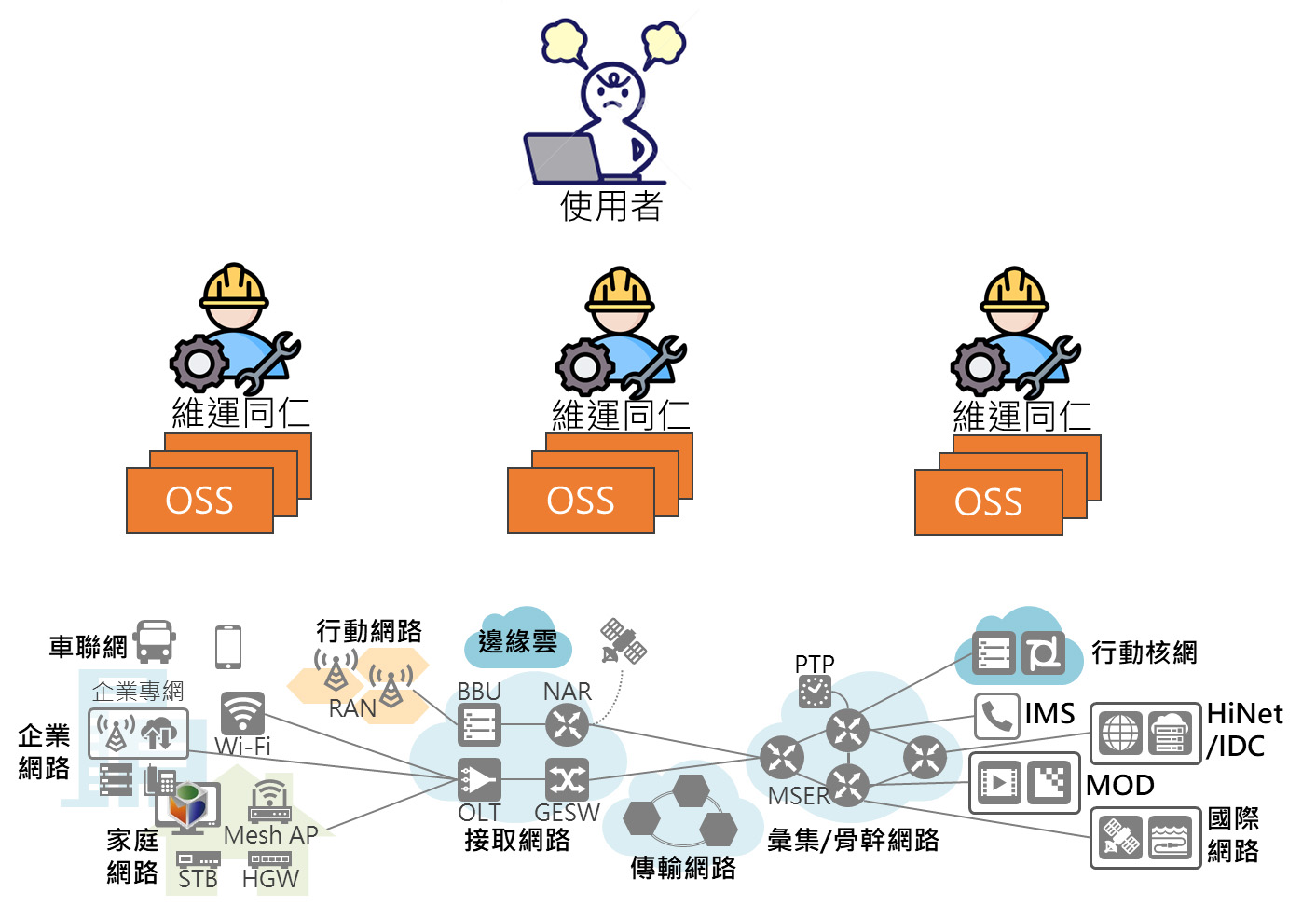
大語言模型具有出色的自然語言處理能力,能夠理解和生成自然語言文本。在網路維運領域可以應用於多個方面:
日誌分析: 大語言模型可以幫助分析龐大的日誌文件,識別異常行為、預測故障或瓶頸,以及提供對網路性能和安全性的評估。
申告處理: 大語言模型可以處理客戶申告的文本訊息,快速理解問題並提供相應的解決方案。這能夠提高客戶滿意度並縮短故障處理時間。
報表生成: 大語言模型可以協助自動生成報表,摘要網路性能數據、問題排查結果等,簡化營運和管理的流程。
通訊協作: 大語言模型可以用於自動生成和理解電信專業領域的文本,例如技術文檔、溝通記錄等,促進團隊內的信息交流。
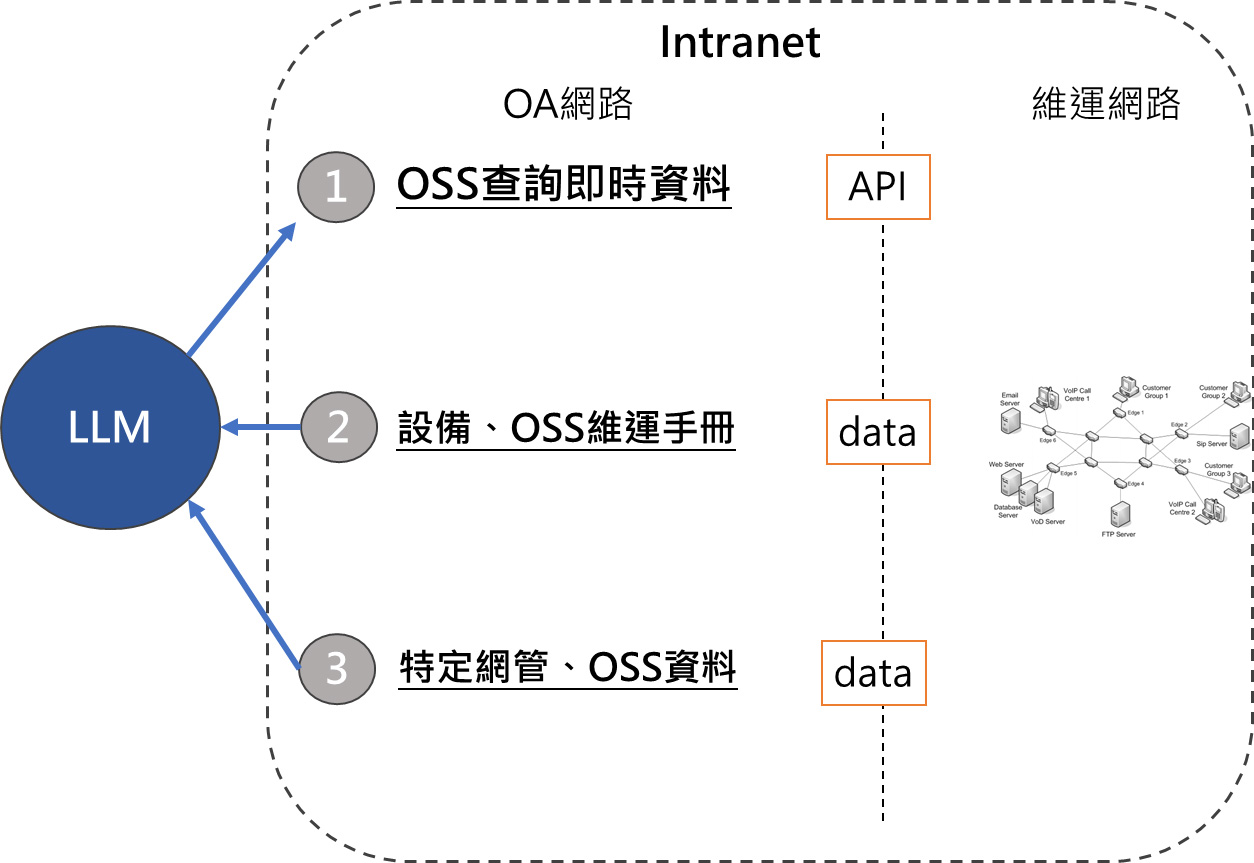
雖然大語言模型可以提高大量文本數據的處理效率、帶來更深層次的智慧分析和預測能力。但電信公司最大的資產就是客戶資料,這也是絕對不能外洩的機密。在第四節中將會介紹如何落地建構安全的應用方式,也就是將環境建構在自己能完全掌握的環境中,而不透過外部網路存取大語言模型。
三、 大語言模型存取方式
對一般使用者而言最簡單的存取方式就是透過網頁存取,網頁甚至不需要使用說明,只要輸入問題就可以得到回答如圖3。
進階使用者譬如希望能串接外部網頁、串聯不同模型、微調模型、教導模型領域知識,則會需要使用到api方式,再自行撰寫程式來呼叫如圖4。
但不管是哪種存取,總是會需要將手上的資料透過網路傳送給提供服務的業者,可能會有許多人開始有疑問是否自己的資料也會被拿去訓練,被當作大語言模型的養分呢?
先講結論: 大部分業者會提供資料使用條款保障(譬如微軟[17]),但使用者只能自求多福。
也因此許多擁有機密資料的公司會想發展私有的大語言模型,環境可以完全掌握在自己手中,但建置屬於自己的大語言模型並不是那麼容易的事情。
在詳細介紹之前需要先根據參數量做簡單的分類: 強語言模型與弱語言模型。
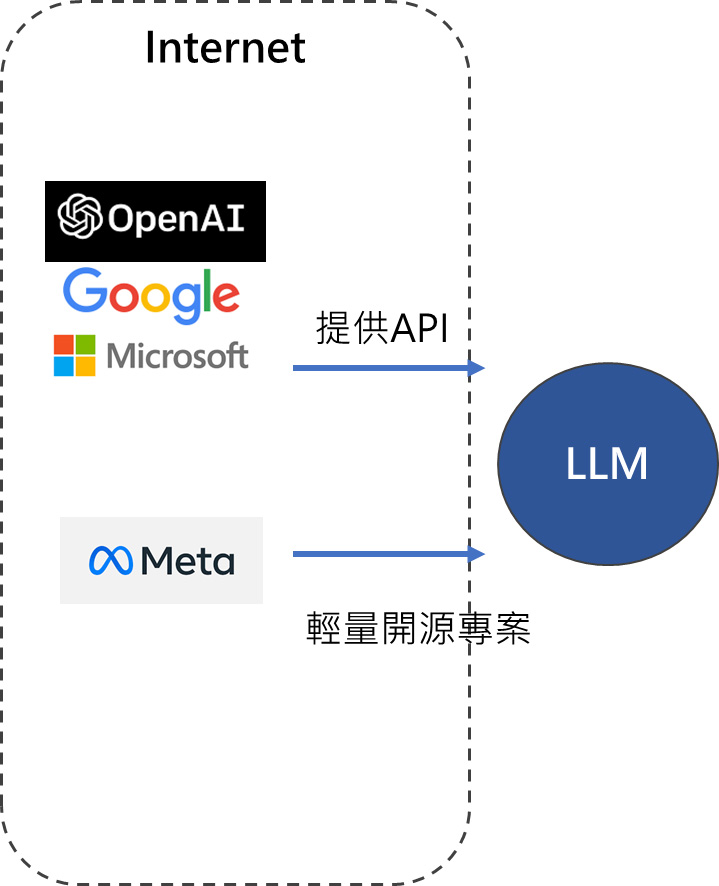
強語言模型如OpenAI的GPT4、Google的PaLM2有極大的參數量(超過5000億),收集並預訓練極多的資料集(超過45TB)。這種模型的建置成本通常極高也因此不太可能將模型落地至客戶端環境中使用,目前業者都以resful API方式提供存取。
弱語言模型如Meta(Facebook)的LLaMa2則是以輕量開源的方式提供下載使用,建置以後只要符合使用規範[18]甚至連商用都是允許的。在下一節中將會介紹如何建置私有大語言模型。
四、 私有大語言模型建置方式
電信公司擁有許多客戶資料,包括個人識別資訊、通訊記錄、移動軌跡、帳務資訊等敏感數據。這些資料的安全性對於公司的信譽和業務運營至關重要。為了確保這些數據不被外洩,電信公司總是採取最嚴謹的安全措施,當然在使用大語言模型的時候也不能例外。
私有大語言模型的使用,提供了更高層次的保密性,因為這些模型運行在受控制的環境中。這意味著數據不會離開公司的內部網路,減少了遭受外部攻擊的風險。同時,這些模型本身應該具有嚴格的訪問控制與存取紀錄,以確保客戶資料的隱私得到保護。
以下以Taiwan-LLaMa為例來介紹如何佈署可完全掌控的私有大語言模型至本地端環境(此專案為台大教授陳縕儂的實驗室基於LLaMa2開發的大語言模型)。
首先到官方提供的HuggingFace專案中下載[19](類似github,但其可以存放預訓練的模型檔案)。單純用網頁提供的下載連結或是git clone整個專案都可以。
符合HuggingFace格式的檔案包含許多binary(二進位檔案)、設定檔與標記器(tokenizer)檔案,要載入使用則須要使用python語言與transformer套件。
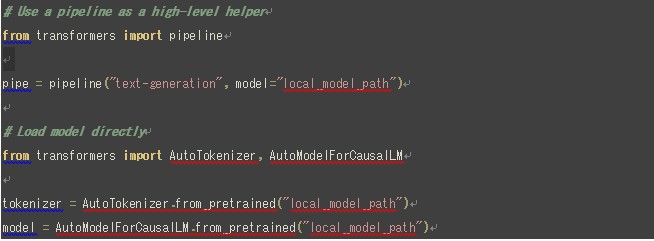
載入完成以後就可以簡單使用transformer套件中的pipeline函式來進行自己想要的操作了[20]。
另外還有一種模型檔案格式為GGUF、GGML,則需要使用llama.cpp框架才能佈署,詳細使用說明可以參考官方說明[21],以此種方式佈署的模型可以降低資源使用還有提高效能。
五、 大語言模型應用方式
光憑上面的介紹還是無法滿足進階使用者的需求(串接外部網頁、串聯不同模型、微調模型、教導模型領域知識),所以這個章節將會介紹幾種適用於各種大語言模型的調教方式。
Fine-tune與Repretrain: 這是兩種可以教導大語言模型更多知識的方式,其中fine-tune需要整理資料為問答格式,常見演算法包含LoRA[22]、LLAMA Efficient Tuning[23]。但在許多的研究指出若模型本身訓練不足,光靠fine-tune很容易發生幻覺(hallucinate),也就是大語言模型會回答出不精準的答案。Repretrain則是整理更多的資料後重新訓練,雖然會耗費許多成本但可以大幅提供模型的精準度,使用方式可以參考Chinese-LLaMA-Alpaca的pretraining程式[24]。
Embedding則是一種RAG(Retrieval Augmented Generation)應用方式,原理是將自定義文本資料以演算法轉為向量格式[25],儲存於向量資料庫後讓大語言模型可以進行更精準的查閱資料。根據NVIDIA的論文[26]指出: 一個應用了RAG檢索的弱語言模型 (LLaMA2-70B),在七個長篇文本任務中表現都優於強語言模型 (GPT-3.5-turbo-16k)。
Langchain[27]或AutoGen[28]則是一種多模態大語言模型[29](Multimodality and Large Multimodal Models,LMMs)的應用方式,在這種框架中的大語言模型不再是一枝獨秀,其強調多種不同用途模型 (包含影像、音訊、程式碼)或是不同領域微調模型的整合,畢竟如人類的大腦也不是一個只會處理單一種類資料的單純系統。
多模態大語言模型可以整合外部API,使大語言模型可以即時查詢最新的網路資料並附上來源、搭配RAG方式查詢特定資料、檢查輸入輸出資料是否包含有害或機密資訊。是目前主流的大語言模型應用框架。
參 結論
大語言模型在網路維運管理領域具有廣泛的實際應用。它可以應用於日誌分析、申告處理、報表生成和通訊協作等多個方面。為了確保資料的安全性,許多公司選擇建立私有的大語言模型,並將其部署在受控制的環境中。私有大語言模型的使用可以提高保密性和隱私保護。此外,本文還介紹了不同的大語言模型應用方式,如Fine-tune、Repretrain、RAG和LMMs。通過採用這些方式,可以進一步提升大語言模型的性能和適用性。因此,大語言模型是網路維運管理的最佳選擇,能夠為企業帶來更佳的智慧分析與人員效能提升,進而提升整體網路穩定度。
肆 參考文獻
[1] “AI聊天機器人ChatGPT 用戶數成長速度創紀錄”https://tech.udn.com/tech/story/123454/6944863
[2] Xavier Amatriain, Ananth Sankar, Jie Bing, Praveen Kumar Bodigutla, Timothy J. Hazen, Michaeel Kazi. “Transformer models: an introduction and catalog” 25 May 2023 . Available at: https://arxiv.org/abs/2302.07730
[3] ChatGPT,https://chat.openai.com/
[4] Claude,https://claude.ai/
[5] Bard,https://bard.google.com/chat?hl=zh-TW
[6] Perplexity,https://www.perplexity.ai/
[7] GitHub Copilot,https://github.com/features/copilot
[8] SQL Chat,https://www.sqlchat.ai/
[9] Midjourney,https://www.midjourney.com/
[10] ChatGPT Vison,https://openai.com/blog/chatgpt-can-now-see-hear-and-speak
[11] Bing Image Creator,https://www.bing.com/create
[12] Leonardo.Ai,https://leonardo.ai/
[13] Speech Synthesis,https://elevenlabs.io/speech-synthesis
[14] Dubs,https://elevenlabs.io/dubbing
[15] VoiceLab,https://elevenlabs.io/voice-lab
[16] Voice Library,https://elevenlabs.io/voice-library
[17] 微軟資料保證,https://learn.microsoft.com/en-us/legal/cognitive-services/openai/data-privacy
[18] LLaMa2使用條款,https://github.com/facebookresearch/llama/blob/main/LICENSE
[19] Taiwan-LLaMa huggingface repo,https://huggingface.co/yentinglin/Taiwan-LLaMa-v1.0
[20] huggingface pipeline使用說明,https://huggingface.co/docs/transformers/pipeline_tutorial
[21] llama.cpp,https://github.com/ggerganov/llama.cpp
[22] LoRa,https://github.com/microsoft/LoRA
[23] LLAMA Efficient Tuning,https://github.com/hiyouga/LLaMA-Efficient-Tuningr
[24] Chinese-LLaMA-Alpaca的pretraining方式,https://github.com/ymcui/Chinese-LLaMA-Alpaca/wiki/Pretraining-script
[25] embedding使用說明,https://huggingface.co/blog/getting-started-with-embeddings
[26] Peng Xu, Wei Ping, Xianchao Wu, Lawrence McAfee, Chen Zhu, Zihan Liu, Sandeep Subramanian, Evelina Bakhturina, Mohammad Shoeybi, Bryan Catanzaro, “Retrieval meets Long Context Large Language Models”,
Available at: https://arxiv.org/abs/2310.03025?fbclid=IwAR16I3gtV_2K16plVff6rTlBU6aorp1ZhJ6jpolZKdApBzaYjhrXqszFPEA
[27] langchain,https://github.com/langchain-ai/langchain
[28] AutoGen,https://github.com/microsoft/autogen
[29] Chip Huyen, “Multimodality and Large Multimodal Models (LMMs)”,
Available at: https://huyenchip.com/2023/10/10/multimodal.html?fbclid=IwAR38A9UToFOeeKm1fsK8jMgqMoyswYp9YxL8hzX2udkfuyhvIIalsKhNxPQ